当地时间8月28日,AI初创公司Cerebra宣布推出Cerebras Inference,据称是目前世界上最快的AI推理解决方案。
随着聊天机器人和其他AIGC应用程序的热度愈来愈高,推理服务成为了AI计算中增长最快的部分,约占整个云端所有AI工作负载的40%左右。
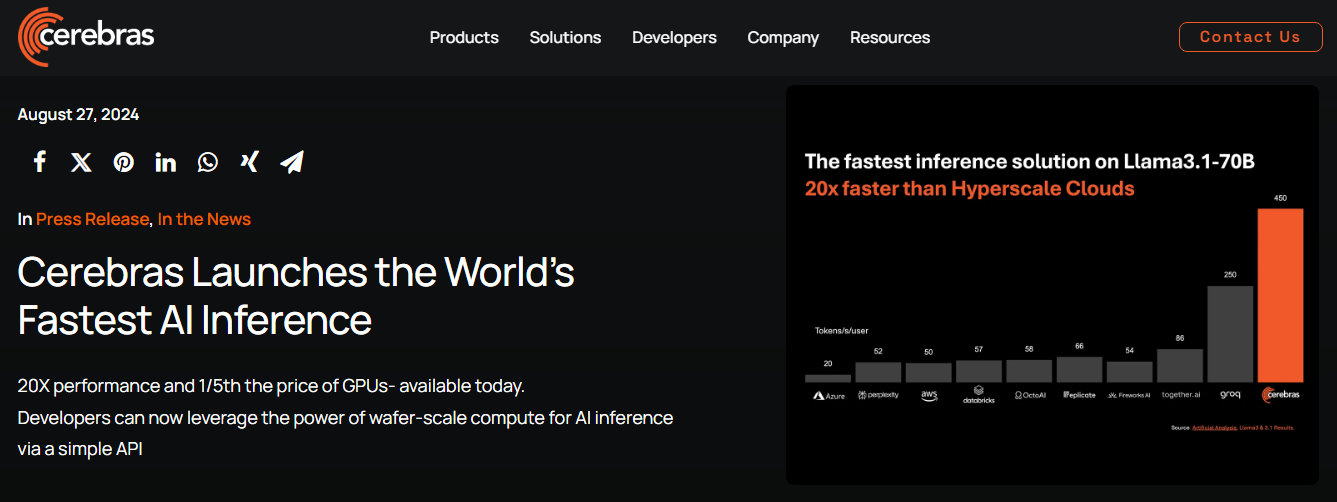
Cerebras是一家专门生产用于AI和HPC及其工作负载的强大计算机芯片的生产商。据其介绍,Cerebras Inference使用了Cerebras CS-3系统及其Wafer Scale Engine 3(WSE-3)AI处理器,前者的内存带宽是英伟达H100的7,000倍,而后者的内核数量是单个英伟达H100的52倍。
该公司还声称:“Cerebras Inference为Llama 3.18B每秒提供1,800个token,为Llama 3.170B每秒提供450个token,比微软Azure等超大规模云中基于英伟达最新一代Hopper GPU的解决方案快20倍。”
凭借创纪录的性能、业界领先的定价和开放的API访问,Cerebras Inference 为开放的LLM开发和部署设定了新标准。Cerebras的创始人兼首席执行官Andrew Feldman认为,这种超高速AI推理将为AI的采用带来巨大机遇。
据了解,Cerebras Inference共有以下三个层级:


全部评论